Based on paper: https://arxiv.org/abs/1812.11941
The human brain possesses the remarkable ability to infer depth when viewing a two-dimensional scene, even with a single-point measurement, as in viewing a photograph. However, accurate depth mapping from a single image remains a challenge in computer vision. Depth informationfrom a scene is valuable for many tasks like augmented reality, robotics, self driving cars etc. In this blog we explore how to train a depth estimation model on NYU Depth Data set. The model gets state of the art results on this data set. We also add code to test this model on images + videos collected by the user.
The trained model performs very well on data from the wild as shown in the video below.
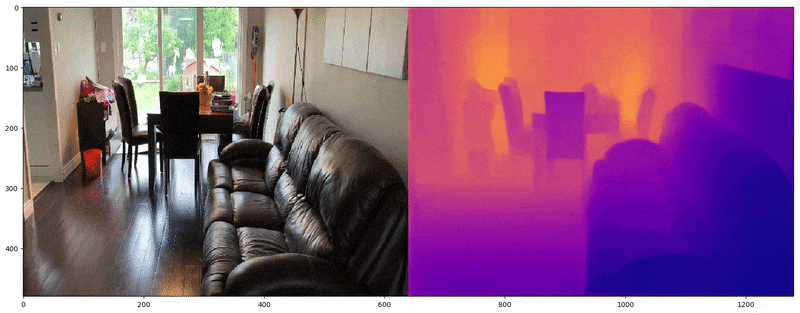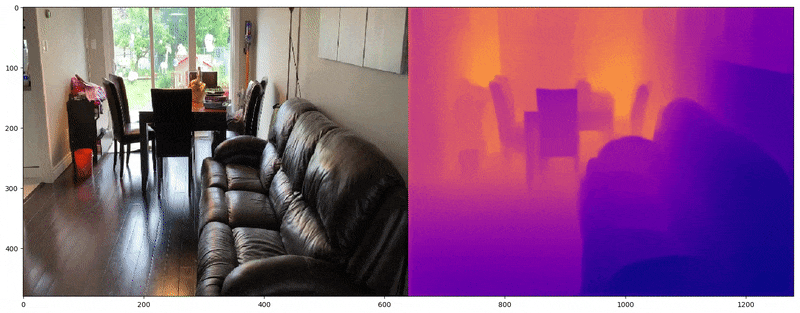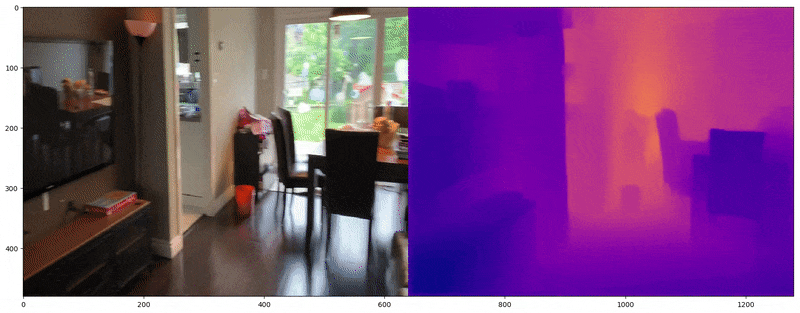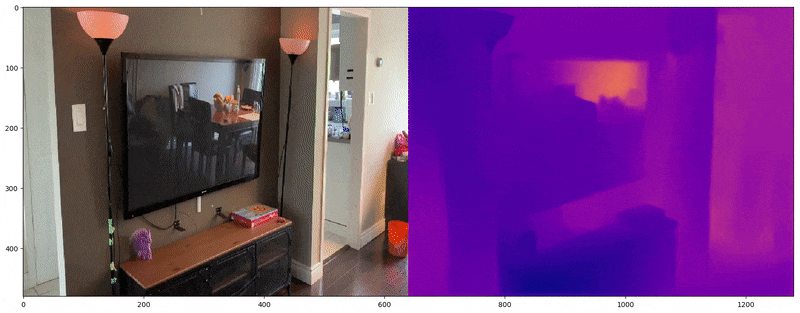
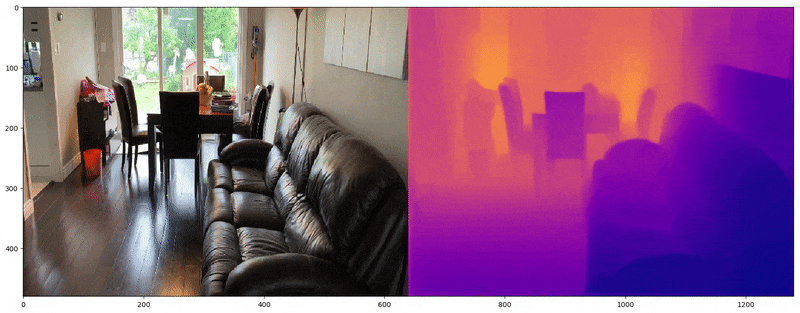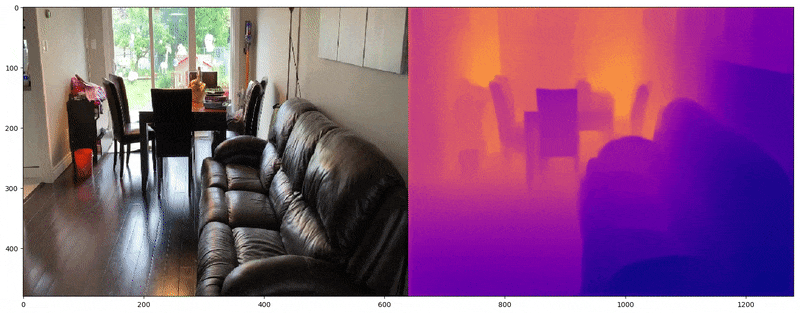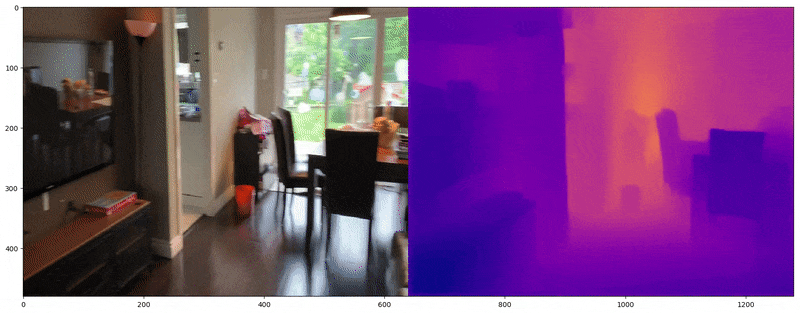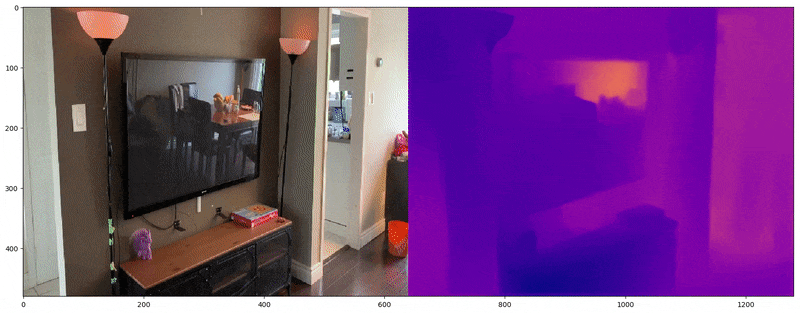
Actual Image on left and predicted depth map on the right
The full code is open sourced on my Github repo.
What does the depth information look like? Depth can be stored as the distance from the camera in meters for each pixel in the image frame. Figure below shows the depth map for a single RGB image. The depth map is on the right where actual depth has been converted to relative depth using the maximum depth of this room.

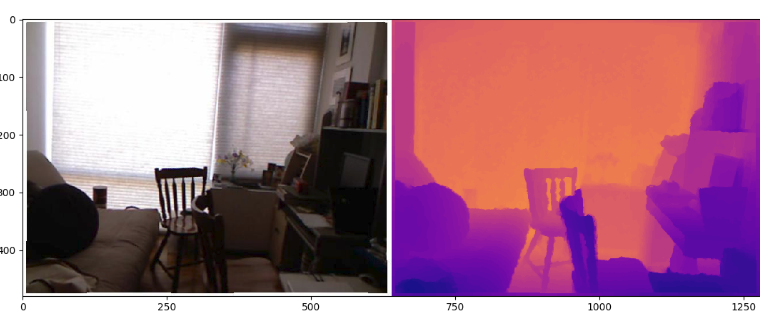
RGB Image and its corresponding depth map
To build a depth estimation model, we need RGB images and corresponding depth information. Depth information can be collected through low cost sensors like Kinect. For this exercise, I have used the popular NYU v2 depth data set to build a model. This data set consists of over 400,000 images and their corresponding depth maps. I used a subset of 50,000 images from the overall data set for the training task.
I read through several papers that perform the task of depth estimation and many of them use an encoder decoder type neural network. For depth estimation task, the input to the model is a RGB image and the output is a depth image which is either the same dimension as the input image or sometimes scaled down version of the input image with the same aspect ratio.A standard loss function used for this task considers difference between the actual and predicted depth map. This can be L1 or L2 loss.
I decided to work with the Dense Depth model from Alhashim and Wonka. This model is impressive in its simplicity and its accuracy. It is easy to understand and relatively fast to train. It uses image augmentation and a custom loss function to get better results than from more complex architectures. This model uses the powerful DenseNet model with pretrained weights to power the Encoder.
Dense Depth Model
The encoder presented in the paper is a pretrained DenseNet 169. Theencoder consists of 4 dense blocks that occur before the fully connected layers in the DenseNet 169 model. It is different from other depth models in that it uses a very simple decoder. Each decoder block consists of a single bi-linear upsampling layer followed by 2 convolution layers. Following another standard practice in encoder decoder architecture, the up sampling layers are concatenated with the corresponding layers in the encoder. Figure below, explains the architecture in more detail. For more details on layers please read the original paper. It is very well written!